GPT-4o-mini 파인튜닝 실습 (ipynb)¶
파인튜닝은 프롬프트에 담을 수 있는 것보다 훨씬 더 많은 예제를 학습시켜 모델을 개선하고, 다양한 작업에서 더 나은 결과를 얻을 수 있게 합니다.
이 ipynb 노트북은 새로운 GPT-4o-mini 파인튜닝을 위한 가이드를 제공합니다.
RecipeNLG 데이터셋을 사용하여 엔티티 추출을 수행할 것입니다.
이 데이터셋은 다양한 레시피와 각 레시피에 대한 일반적인 재료 목록을 제공합니다.
이는 명명된 엔티티 인식(NER) 작업에 흔히 사용되는 데이터셋입니다.
(참고) GPT-4o 미니 파인튜닝은 Tier 4 및 5 사용 등급에서 개발자에게 제공됩니다. (바뀔 수 있으니 확인해보세요!)
OpenAI 파인튜닝 대시보드 : https://platform.openai.com/finetune¶
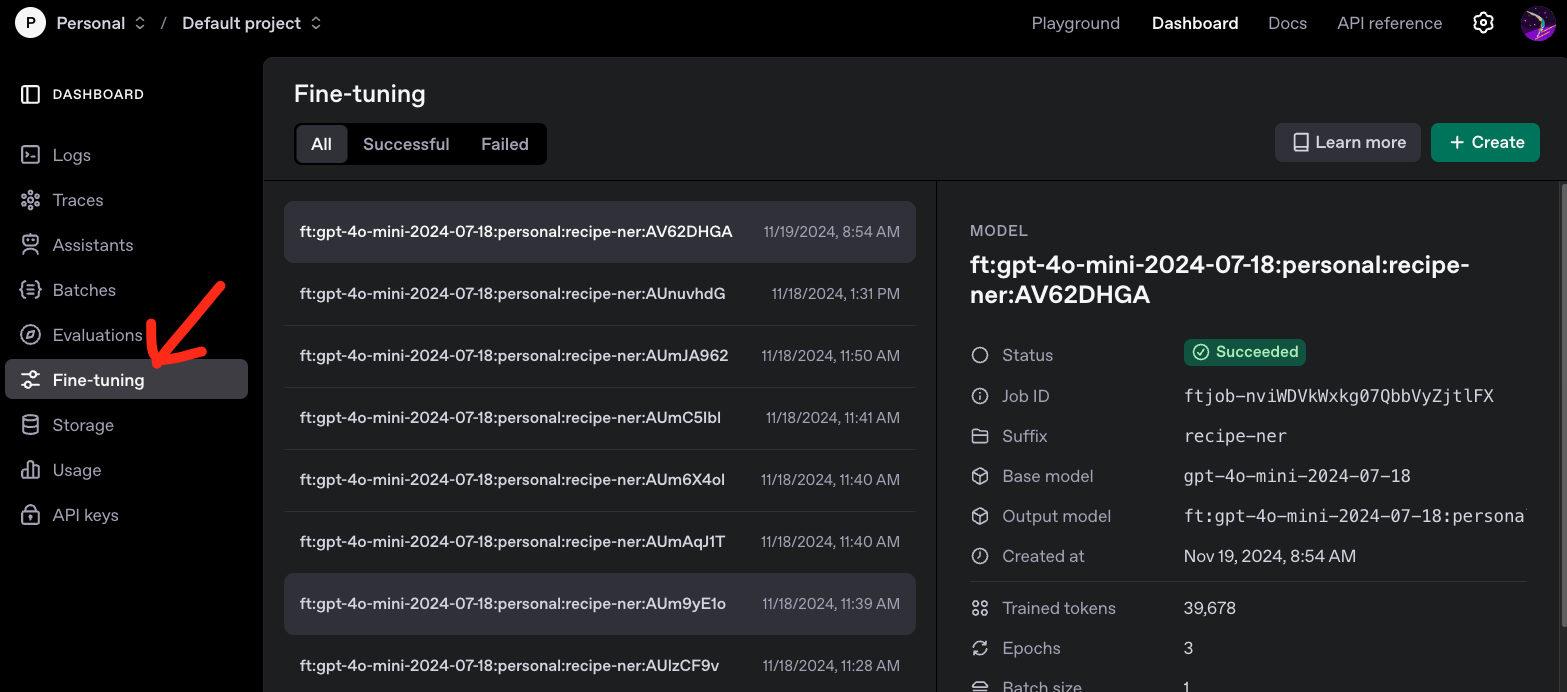
파인튜닝 대시보드를 방문하여 "Create"을 클릭하고 기본 모델 드롭다운에서 "gpt-4o-mini-2024-07-18"을 선택하여 GPT-4o 미니 파인튜닝을 시작할 수 있습니다.
- 설정: 데이터셋을 로드하고 파인튜닝할 도메인으로 필터링합니다.
- 데이터 준비: 학습 및 검증 예제를 생성하고 이를
Files엔드포인트에 업로드하여 파인튜닝을 위한 데이터를 준비합니다. - 파인튜닝: 파인튜닝된 모델을 생성합니다.
- 추론: 새로운 입력에 대해 파인튜닝된 모델을 사용하여 추론을 수행합니다.
이 과정을 마치면 gpt-4o-mini-2024-07-18 모델을 학습, 평가 및 배포할 수 있게 될 것입니다.
파인튜닝에 대한 더 많은 정보는 문서 가이드 또는 API 참조를 참조하세요.
본 실습은 OpenAI 에서 발행한 Cookbook 입니다.
Setup¶
# make sure to use the latest version of the openai python package
!pip install --upgrade --quiet openai
import json
import openai
import os
import pandas as pd
from pprint import pprint
client = openai.OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
organization="<org id>",
project="<project id>",
)
Fine-tuning works best when focused on a particular domain. It's important to make sure your dataset is both focused enough for the model to learn, but general enough that unseen examples won't be missed. Having this in mind, we have extracted a subset from the RecipesNLG dataset to only contain documents from cookbooks.com.
# Read in the dataset we'll use for this task.
# This will be the RecipesNLG dataset, which we've cleaned to only contain documents from www.cookbooks.com
recipe_df = pd.read_csv("data/cookbook_recipes_nlg_10k.csv")
recipe_df.head()
| title | ingredients | directions | link | source | NER | |
|---|---|---|---|---|---|---|
| 0 | No-Bake Nut Cookies | ["1 c. firmly packed brown sugar", "1/2 c. eva... | ["In a heavy 2-quart saucepan, mix brown sugar... | www.cookbooks.com/Recipe-Details.aspx?id=44874 | www.cookbooks.com | ["brown sugar", "milk", "vanilla", "nuts", "bu... |
| 1 | Jewell Ball'S Chicken | ["1 small jar chipped beef, cut up", "4 boned ... | ["Place chipped beef on bottom of baking dish.... | www.cookbooks.com/Recipe-Details.aspx?id=699419 | www.cookbooks.com | ["beef", "chicken breasts", "cream of mushroom... |
| 2 | Creamy Corn | ["2 (16 oz.) pkg. frozen corn", "1 (8 oz.) pkg... | ["In a slow cooker, combine all ingredients. C... | www.cookbooks.com/Recipe-Details.aspx?id=10570 | www.cookbooks.com | ["frozen corn", "cream cheese", "butter", "gar... |
| 3 | Chicken Funny | ["1 large whole chicken", "2 (10 1/2 oz.) cans... | ["Boil and debone chicken.", "Put bite size pi... | www.cookbooks.com/Recipe-Details.aspx?id=897570 | www.cookbooks.com | ["chicken", "chicken gravy", "cream of mushroo... |
| 4 | Reeses Cups(Candy) | ["1 c. peanut butter", "3/4 c. graham cracker ... | ["Combine first four ingredients and press in ... | www.cookbooks.com/Recipe-Details.aspx?id=659239 | www.cookbooks.com | ["peanut butter", "graham cracker crumbs", "bu... |
Data preparation¶
We'll begin by preparing our data. When fine-tuning with the ChatCompletion format, each training example is a simple list of messages. For example, an entry could look like:
[{'role': 'system',
'content': 'You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided.'},
{'role': 'user',
'content': 'Title: No-Bake Nut Cookies\n\nIngredients: ["1 c. firmly packed brown sugar", "1/2 c. evaporated milk", "1/2 tsp. vanilla", "1/2 c. broken nuts (pecans)", "2 Tbsp. butter or margarine", "3 1/2 c. bite size shredded rice biscuits"]\n\nGeneric ingredients: '},
{'role': 'assistant',
'content': '["brown sugar", "milk", "vanilla", "nuts", "butter", "bite size shredded rice biscuits"]'}]
During the training process this conversation will be split, with the final entry being the completion that the model will produce, and the remainder of the messages acting as the prompt. Consider this when building your training examples - if your model will act on multi-turn conversations, then please provide representative examples so it doesn't perform poorly when the conversation starts to expand.
Please note that currently there is a 4096 token limit for each training example. Anything longer than this will be truncated at 4096 tokens.
system_message = "You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided."
def create_user_message(row):
return f"Title: {row['title']}\n\nIngredients: {row['ingredients']}\n\nGeneric ingredients: "
def prepare_example_conversation(row):
return {
"messages": [
{"role": "system", "content": system_message},
{"role": "user", "content": create_user_message(row)},
{"role": "assistant", "content": row["NER"]},
]
}
pprint(prepare_example_conversation(recipe_df.iloc[0]))
{'messages': [{'content': 'You are a helpful recipe assistant. You are to '
'extract the generic ingredients from each of the '
'recipes provided.',
'role': 'system'},
{'content': 'Title: No-Bake Nut Cookies\n'
'\n'
'Ingredients: ["1 c. firmly packed brown sugar", '
'"1/2 c. evaporated milk", "1/2 tsp. vanilla", "1/2 '
'c. broken nuts (pecans)", "2 Tbsp. butter or '
'margarine", "3 1/2 c. bite size shredded rice '
'biscuits"]\n'
'\n'
'Generic ingredients: ',
'role': 'user'},
{'content': '["brown sugar", "milk", "vanilla", "nuts", '
'"butter", "bite size shredded rice biscuits"]',
'role': 'assistant'}]}
Let's now do this for a subset of the dataset to use as our training data. You can begin with even 30-50 well-pruned examples. You should see performance continue to scale linearly as you increase the size of the training set, but your jobs will also take longer.
# use the first 100 rows of the dataset for training
training_df = recipe_df.loc[0:100]
# apply the prepare_example_conversation function to each row of the training_df
training_data = training_df.apply(prepare_example_conversation, axis=1).tolist()
for example in training_data[:5]:
print(example)
{'messages': [{'role': 'system', 'content': 'You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided.'}, {'role': 'user', 'content': 'Title: No-Bake Nut Cookies\n\nIngredients: ["1 c. firmly packed brown sugar", "1/2 c. evaporated milk", "1/2 tsp. vanilla", "1/2 c. broken nuts (pecans)", "2 Tbsp. butter or margarine", "3 1/2 c. bite size shredded rice biscuits"]\n\nGeneric ingredients: '}, {'role': 'assistant', 'content': '["brown sugar", "milk", "vanilla", "nuts", "butter", "bite size shredded rice biscuits"]'}]}
{'messages': [{'role': 'system', 'content': 'You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided.'}, {'role': 'user', 'content': 'Title: Jewell Ball\'S Chicken\n\nIngredients: ["1 small jar chipped beef, cut up", "4 boned chicken breasts", "1 can cream of mushroom soup", "1 carton sour cream"]\n\nGeneric ingredients: '}, {'role': 'assistant', 'content': '["beef", "chicken breasts", "cream of mushroom soup", "sour cream"]'}]}
{'messages': [{'role': 'system', 'content': 'You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided.'}, {'role': 'user', 'content': 'Title: Creamy Corn\n\nIngredients: ["2 (16 oz.) pkg. frozen corn", "1 (8 oz.) pkg. cream cheese, cubed", "1/3 c. butter, cubed", "1/2 tsp. garlic powder", "1/2 tsp. salt", "1/4 tsp. pepper"]\n\nGeneric ingredients: '}, {'role': 'assistant', 'content': '["frozen corn", "cream cheese", "butter", "garlic powder", "salt", "pepper"]'}]}
{'messages': [{'role': 'system', 'content': 'You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided.'}, {'role': 'user', 'content': 'Title: Chicken Funny\n\nIngredients: ["1 large whole chicken", "2 (10 1/2 oz.) cans chicken gravy", "1 (10 1/2 oz.) can cream of mushroom soup", "1 (6 oz.) box Stove Top stuffing", "4 oz. shredded cheese"]\n\nGeneric ingredients: '}, {'role': 'assistant', 'content': '["chicken", "chicken gravy", "cream of mushroom soup", "shredded cheese"]'}]}
{'messages': [{'role': 'system', 'content': 'You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided.'}, {'role': 'user', 'content': 'Title: Reeses Cups(Candy) \n\nIngredients: ["1 c. peanut butter", "3/4 c. graham cracker crumbs", "1 c. melted butter", "1 lb. (3 1/2 c.) powdered sugar", "1 large pkg. chocolate chips"]\n\nGeneric ingredients: '}, {'role': 'assistant', 'content': '["peanut butter", "graham cracker crumbs", "butter", "powdered sugar", "chocolate chips"]'}]}
In addition to training data, we can also optionally provide validation data, which will be used to make sure that the model does not overfit your training set.
validation_df = recipe_df.loc[101:200]
validation_data = validation_df.apply(
prepare_example_conversation, axis=1).tolist()
We then need to save our data as .jsonl files, with each line being one training example conversation.
def write_jsonl(data_list: list, filename: str) -> None:
with open(filename, "w") as out:
for ddict in data_list:
jout = json.dumps(ddict) + "\n"
out.write(jout)
training_file_name = "tmp_recipe_finetune_training.jsonl"
write_jsonl(training_data, training_file_name)
validation_file_name = "tmp_recipe_finetune_validation.jsonl"
write_jsonl(validation_data, validation_file_name)
This is what the first 5 lines of our training .jsonl file look like:
# print the first 5 lines of the training file
!head -n 5 tmp_recipe_finetune_training.jsonl
{"messages": [{"role": "system", "content": "You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided."}, {"role": "user", "content": "Title: No-Bake Nut Cookies\n\nIngredients: [\"1 c. firmly packed brown sugar\", \"1/2 c. evaporated milk\", \"1/2 tsp. vanilla\", \"1/2 c. broken nuts (pecans)\", \"2 Tbsp. butter or margarine\", \"3 1/2 c. bite size shredded rice biscuits\"]\n\nGeneric ingredients: "}, {"role": "assistant", "content": "[\"brown sugar\", \"milk\", \"vanilla\", \"nuts\", \"butter\", \"bite size shredded rice biscuits\"]"}]}
{"messages": [{"role": "system", "content": "You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided."}, {"role": "user", "content": "Title: Jewell Ball'S Chicken\n\nIngredients: [\"1 small jar chipped beef, cut up\", \"4 boned chicken breasts\", \"1 can cream of mushroom soup\", \"1 carton sour cream\"]\n\nGeneric ingredients: "}, {"role": "assistant", "content": "[\"beef\", \"chicken breasts\", \"cream of mushroom soup\", \"sour cream\"]"}]}
{"messages": [{"role": "system", "content": "You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided."}, {"role": "user", "content": "Title: Creamy Corn\n\nIngredients: [\"2 (16 oz.) pkg. frozen corn\", \"1 (8 oz.) pkg. cream cheese, cubed\", \"1/3 c. butter, cubed\", \"1/2 tsp. garlic powder\", \"1/2 tsp. salt\", \"1/4 tsp. pepper\"]\n\nGeneric ingredients: "}, {"role": "assistant", "content": "[\"frozen corn\", \"cream cheese\", \"butter\", \"garlic powder\", \"salt\", \"pepper\"]"}]}
{"messages": [{"role": "system", "content": "You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided."}, {"role": "user", "content": "Title: Chicken Funny\n\nIngredients: [\"1 large whole chicken\", \"2 (10 1/2 oz.) cans chicken gravy\", \"1 (10 1/2 oz.) can cream of mushroom soup\", \"1 (6 oz.) box Stove Top stuffing\", \"4 oz. shredded cheese\"]\n\nGeneric ingredients: "}, {"role": "assistant", "content": "[\"chicken\", \"chicken gravy\", \"cream of mushroom soup\", \"shredded cheese\"]"}]}
{"messages": [{"role": "system", "content": "You are a helpful recipe assistant. You are to extract the generic ingredients from each of the recipes provided."}, {"role": "user", "content": "Title: Reeses Cups(Candy) \n\nIngredients: [\"1 c. peanut butter\", \"3/4 c. graham cracker crumbs\", \"1 c. melted butter\", \"1 lb. (3 1/2 c.) powdered sugar\", \"1 large pkg. chocolate chips\"]\n\nGeneric ingredients: "}, {"role": "assistant", "content": "[\"peanut butter\", \"graham cracker crumbs\", \"butter\", \"powdered sugar\", \"chocolate chips\"]"}]}
Upload files¶
You can now upload the files to our Files endpoint to be used by the fine-tuned model.
def upload_file(file_name: str, purpose: str) -> str:
with open(file_name, "rb") as file_fd:
response = client.files.create(file=file_fd, purpose=purpose)
return response.id
training_file_id = upload_file(training_file_name, "fine-tune")
validation_file_id = upload_file(validation_file_name, "fine-tune")
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Training file ID: file-3wfAfDoYcGrSpaE17qK0vXT0 Validation file ID: file-HhFhnyGJhazYdPcd3wrtvIoX
Fine-tuning¶
Now we can create our fine-tuning job with the generated files and an optional suffix to identify the model. The response will contain an id which you can use to retrieve updates on the job.
Note: The files have to first be processed by our system, so you might get a File not ready error. In that case, simply retry a few minutes later.
MODEL = "gpt-4o-mini-2024-07-18"
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model=MODEL,
suffix="recipe-ner",
)
job_id = response.id
print("Job ID:", response.id)
print("Status:", response.status)
Job ID: ftjob-UiaiLwGdGBfdLQDBAoQheufN Status: validating_files
Check job status¶
You can make a GET request to the https://api.openai.com/v1/alpha/fine-tunes endpoint to list your alpha fine-tune jobs. In this instance you'll want to check that the ID you got from the previous step ends up as status: succeeded.
Once it is completed, you can use the result_files to sample the results from the validation set (if you uploaded one), and use the ID from the fine_tuned_model parameter to invoke your trained model.
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print("Trained Tokens:", response.trained_tokens)
Job ID: ftjob-UiaiLwGdGBfdLQDBAoQheufN Status: running Trained Tokens: None
We can track the progress of the fine-tune with the events endpoint. You can rerun the cell below a few times until the fine-tune is ready.
response = client.fine_tuning.jobs.list_events(job_id)
events = response.data
events.reverse()
for event in events:
print(event.message)
Step 288/303: training loss=0.00 Step 289/303: training loss=0.01 Step 290/303: training loss=0.00, validation loss=0.31 Step 291/303: training loss=0.00 Step 292/303: training loss=0.00 Step 293/303: training loss=0.00 Step 294/303: training loss=0.00 Step 295/303: training loss=0.00 Step 296/303: training loss=0.00 Step 297/303: training loss=0.00 Step 298/303: training loss=0.01 Step 299/303: training loss=0.00 Step 300/303: training loss=0.00, validation loss=0.04 Step 301/303: training loss=0.16 Step 302/303: training loss=0.00 Step 303/303: training loss=0.00, full validation loss=0.33 Checkpoint created at step 101 with Snapshot ID: ft:gpt-4o-mini-2024-07-18:openai-gtm:recipe-ner:9o1eNlSa:ckpt-step-101 Checkpoint created at step 202 with Snapshot ID: ft:gpt-4o-mini-2024-07-18:openai-gtm:recipe-ner:9o1eNFnj:ckpt-step-202 New fine-tuned model created: ft:gpt-4o-mini-2024-07-18:openai-gtm:recipe-ner:9o1eNNKO The job has successfully completed
Now that it's done, we can get a fine-tuned model ID from the job:
response = client.fine_tuning.jobs.retrieve(job_id)
fine_tuned_model_id = response.fine_tuned_model
if fine_tuned_model_id is None:
raise RuntimeError(
"Fine-tuned model ID not found. Your job has likely not been completed yet."
)
print("Fine-tuned model ID:", fine_tuned_model_id)
Fine-tuned model ID: ft:gpt-4o-mini-2024-07-18:openai-gtm:recipe-ner:9o1eNNKO
Inference¶
The last step is to use your fine-tuned model for inference. Similar to the classic FineTuning, you simply call ChatCompletions with your new fine-tuned model name filling the model parameter.
test_df = recipe_df.loc[201:300]
test_row = test_df.iloc[0]
test_messages = []
test_messages.append({"role": "system", "content": system_message})
user_message = create_user_message(test_row)
test_messages.append({"role": "user", "content": user_message})
pprint(test_messages)
[{'content': 'You are a helpful recipe assistant. You are to extract the '
'generic ingredients from each of the recipes provided.',
'role': 'system'},
{'content': 'Title: Beef Brisket\n'
'\n'
'Ingredients: ["4 lb. beef brisket", "1 c. catsup", "1 c. water", '
'"1/2 onion, minced", "2 Tbsp. cider vinegar", "1 Tbsp. prepared '
'horseradish", "1 Tbsp. prepared mustard", "1 tsp. salt", "1/2 '
'tsp. pepper"]\n'
'\n'
'Generic ingredients: ',
'role': 'user'}]
response = client.chat.completions.create(
model=fine_tuned_model_id, messages=test_messages, temperature=0, max_tokens=500
)
print(response.choices[0].message.content)
["beef brisket", "catsup", "water", "onion", "cider vinegar", "horseradish", "mustard", "salt", "pepper"]
Conclusion¶
Congratulations, you are now ready to fine-tune your own models using the ChatCompletion format! We look forward to seeing what you build